Formati di Compressione
Nel tempo sono emersi vari formati di compressione video, associati a diversi standard:
- ITU-T Standard:
- H.261 (1984)
- H.263, H.263+, H.263++ (1992-2000~)
- Joint ITU-T / MPEG Standard:
- H.262/MPEG-2 (1994)
- H.264 (2004)
- MPEG Standard:
- MPEG-1 (1991)
- MPEG-4 (1998)
Tratteremo brevemente MPEG-1, 2 e 4, per poi approfondire più in dettaglio H.264.
MP3 != MPEG-3
Nota Bene: il popolare formato MP3 non è MPEG-3, che non è mai arrivato ad esistere ed è successivamente stato inglobato in MPEG-4, ma bensì MPEG-1 Audio Layer III
Classificazione dei Frame
Per la compressione video, sfruttiamo la ridondanza temporale innata dei video. Essendo sequenze di immagini, supponiamo che ci siano frame simili tra loro.
I-Frame
Intra, Indipendent Frames (alias: Key-Frames).
I fotogrammi sono codificati senza alcun riferimento ad altri fotogrammi. Rappresentano perciò uno “snapshot” della scena in un determinato istante.
Un I-Frame può essere generato da un encoder per creare un punto di accesso casuale: Ossia permettono ad un decodificatore di avviare il processo di decodifica in maniera corretta, partendo da zero in quella posizione del video.
Gli encoder inseriscono periodicamente I-Frame in un flusso video proprio per avere dei punti di ancoraggio nel video.
Accesso Casuale Video
In altre parole, avere I-Frame nel mezzo di una sequenza video permette di evitare un accesso sequenziale al video. Per esempio, nei servizi di streaming video, questo rende possibile la scelta di andare avanti e indietro nel video con un click a nostro piacimento.
In genere, gli I-Frame richiedono più bit per essere codificati rispetto ad altri tipi di frame. Sono usati come riferimento per la decodifica di altre immagini nel flusso video. Si possono usare altri algoritmi di compressione per rappresentare gli I-Frame in maniera più efficiente (come ad esempio la DCT).
P-Frame
Predicted, Previous-dependent frame.
Ha una dipendenza temporale da quello che è avvenuto prima nel video: devo aver decodificato tutti i frame precedenti, per poter decodificare un P-Frame.
Può contenere:
- I dati del fotogramma;
- Gli spostamenti (i motion vector) rispetto al fotogramma da cui dipende;
- Oppure una combinazione dei due. In generale dunque, un P-Frame contiene solo le differenze rispetto al frame precedente, e per questo motivo richiede meno bit per la codifica rispetto ad un I-Frame.
In un flusso video, i P-Frames sono tipicamente posizionati in mezzo ad I-Frames. La sequenza inizia con un I-Frame, seguita da una serie di P-Frames.
B-Frame
Bidirectional Predicted, Bidirectional-dependent frames.
Possono dipendere anche da frame successivi rispetto alla loro posizione, o in altre parole, dipendono da un intorno di frames.
Hanno il miglior rapporto di compressione.
Un B-Frame richiede la precedente decodifica di altri frames prima di essere decodificato.
Può contenere gli stessi dati di un P-Frame.
Inserire in un fotogramma informazioni che si riferiscono ad un fotogramma successivo è possibile solo alterando l’ordine in cui i fotogrammi vengono archiviati all’interno del file video compresso.
I B-Frame possono essere posizionati in mezzo a I-Frames e P-Frames.
Memorizzazione Frame
Interdipendenza Frame
In generale, evito interdipendenza tra frame. Ad esempio, un P-Frame può dipendere da I-Frames o anche da altri P-Frames, ma non da B-Frames. Un B-Frame può dipendere sia da P-Frames che I-Frames.
Consideriamo la sequenza di frame (f) con relativi macroblocchi (ma):
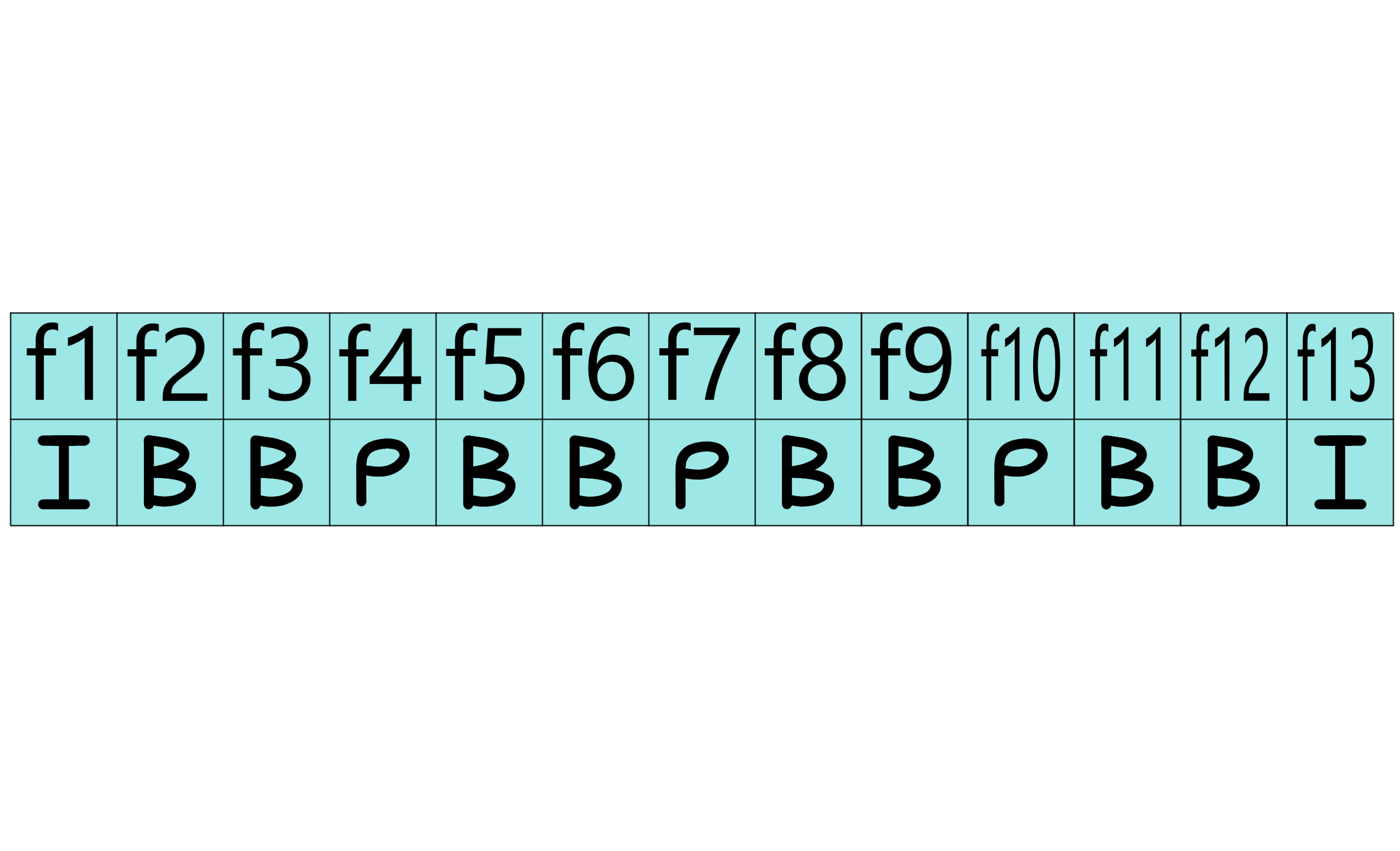
Esempio Memorizzazione (possibile domanda esame):
i
del f1 sono tutti codificati come Intra-Frame i
del f2 cercheranno i blocchi simili nel f1 (I) e nel f4 (P) i
del f3 cercheranno i blocchi simili nel f1 (I) e nel f4 (P) i
del f4 cercheranno i blocchi simili nel f1 (I) i
del f5 cercheranno i blocchi simili nel f4 (P) e nel f7 (P) i
del f6 cercheranno i blocchi simili nel f4 (P) e nel f7 (P) i
del f7 cercheranno i blocchi simili nel f4 (P) i
del f8 cercheranno i blocchi simili nel f7 (P) e nel f10 (P) i
del f9 cercheranno i blocchi simili nel f7 (P) e nel f10 (P) i
del f10 cercheranno i blocchi simili nel f7 i
del f11 cercheranno i blocchi simili nel f10 (P) e nel f13 (I) i
del f12 cercheranno i blocchi simili nel f10 (P) e nel f13 (I) i
del f13 sono tutti codificati come Intra-Frame. La sequenza è conclusa.
Ma come fanno i frame B a riferirsi a frame che “devono ancora arrivare” nel flusso video?
L’Encoder e il decoder processano i frame in ordine diverso da quello iniziale. I frame vengono riordinati per evitare di eseguire “salti” quando incontro B-Frame nel flusso video.
La sequenza precedente viene infatti così riordinata:

Come regola generale ‘euristica’, assolutamente non ufficiale e non verificata: I B-Frame vanno sempre dopo i frame da cui dipendono nel “futuro” nella sequenza iniziale.
In altre parole, sposto “di dietro” ai B-Frames i P-Frames e gli I-Frames.
MPEG-1
L’obiettivo di questo formato era il raggiungimento della qualità VHS: per ottenerla, il video è così codificato:
- La luminosità è a 352x288 pixel (PAL);
- Mentre per quanto riguarda il colore l’immagine è ulteriormente divisa per due e pertanto è codificata a 176x144, perché la crominanza in spazio YCbCr è sottocampionata con un rapporto 4:2:0
MPEG-1 codifica 6 blocchi 8x8: 4 per la luminanza, e 2 per la crominanza.
Il codec MPEG-1 effettua una serie di operazioni di compressione delle immagini che sfruttano non solo la trasformata DCT (ridondanza spaziale), ma anche le differenze tra un fotogramma e l’altro (ridondanza temporale).
Anziché memorizzare tutti i fotogrammi per intero, se ne memorizzano soltanto alcuni come tali ad intervalli prefissati e regolari (cioè gli I-Frames definiti pocanzi.)
Tra di essi ci si limita a memorizzare una serie di frames “incompleti” nel quale vengono scritte solo le informazioni che subiscono variazioni rispetto alle immagini precedenti (ossia i P-Frames e i B-Frames), i cambiamenti vengono salvati comunemente utilizzando i motion vectors.
MPEG-2
L’obiettivo di questo formato era quello di essere flessibile e adatto a varie applicazioni:
- In grado anche di codificare in digitale le immagini con una qualità equivalente a quella analogica;
- in grado di codificare l’audio con una qualità equivalente a quella cinematografica (flussi di dati vino a 60 Mbps).
La caratteristica principale di MPEG-2 è la sua scalabilità:
- Ha la possibilità di creare soluzioni di codifica o decodifica più o meno complesse, as econda del tipo di prodotto da realizzare, aggiungendo poi altre caratteristiche.
- Trasporto parallelo di canali audio, robustezza agli errori di rete, etc…
- Per consentire all’industria di implementare lo standard gradualmente, MPEG ha definito una serie di livelli e profili in base ai quali ogni soluzione tecnica può essere sviluppata e verificata.
- Esistono cinque profili:
- Simple (SP)
- Main (MP)
- SNR Scalable
- Spatial Scalable
- High
- E 4 livelli:
- Low (LL)
- Main (ML)
- High1440 (H-14)
- High (HL)
Inoltre, è importante notare che MPEG-2 non fornisce un suo codec: ognuno può creare una propria implementazione del codec MPEG-2.
Viene solo fornito il decoder: se vengono seguiti gli standard di codifica correttamente, il flusso video verrà decodificato correttamente.
MPEG-4 (cenni)
MPEG-4 usa fondamentalmente lo stesso algoritmo di compressione di MPEG-1,-2, ma in modo molto più efficiente:
- I/P/B-Frames;
- Profili e Livelli
- 32 “Parti” (in realtà 33)
Ogni parte descrive il funzionamento specifico di un sottostandard (ad esempio, compressione dei font nei frame, multiplexing, etc…)
Una funzionalità aggiuntiva di MPEG-4 è che il sistema riesce a distinguere i vari livelli di profondità di un’immagine: lo sfondo e i primi piani.
Questo permette di non memorizzare lo sfondo nel caso in cui rimanga uguale.
Inoltre, è possibile elaborare queste immagini più semplicemente, estrapolando gli attori o gli oggetti dallo sfondo con grande facilità, usando il Virtual Reality Modeling Language (VRML), che permette di rappresentare in formato testuale mesh 3D.
NdR
In realtà, cercando sul web, e come è facilmente intuibile, VRML ha subito molte critiche ai tempi ed è stato scarsamente utilizzato. Viene addirittura superato da Quake.
Dal 2002, MPEG-4 sfrutta al suo interno QuickTime per aumentare le potenzialità di trasmissione dati via web. QuickTime è un formato file “contenitore”.