Stima del Movimento
Telecamera
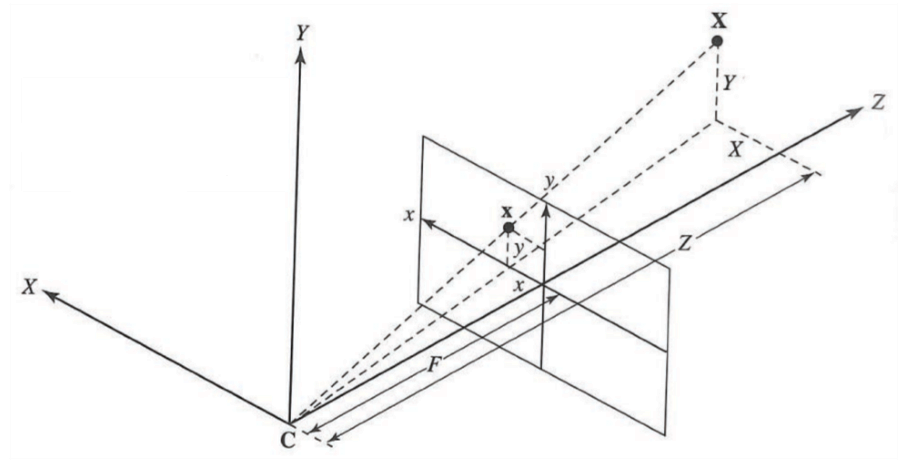
Siano:
- F: Lunghezza Focale;
- C: centro focale;
- Z: Profondità
Prospettica
Assumiamo che:
- L’origine del sistema di coordinate 3D globale sia localizzata in C;
- Il piano XY sia parallelo al piano xy (nel sistema di coordinate dell’immagine);
- Il sistema di riferimento globale e quello dell’immagine usino la stessa unità di misura.
Sistema con Prospettiva: la dimensione di un’oggetto sull’immagine è inversamente proporzionale alla sua distanza.
Se la focale F della camera diminuisce, il piano si avvicina a C, e il punto proiettato in 2D si sposta.
Se aumenta C:
- Il piano si allontana;
- L’oggetto si avvicina.
Proiezioni Prospettiche
Basate su proporzioni.
Ortografica
Assumiamo che gli oggetti da rappresentare nell’immagine siano a distanza (Z) molto grande.
In Ortografia, la dimensione di un oggetto sull’immagine è indipendente dalla sua distanza.
Le proiezioni sono molto semplici:
Dato che non tengo conto della profondità, non mi interessa neanche la focale.
Note sulle proiezioni
Invertibilità: Sia le proiezioni prospettiche che quelle ortografiche stabiliscono una relazione molti-a-uno.
- Per invertire il processo e ricostruire una scena 3D partendo da un’immagine 2D ho bisogno di informazioni aggiuntiva (z-mapping, stereoscopia…);
- Insomma, perdendo la Z, il processo non è facilmente invertibile (al più posso stimare la distanza con regressione).
Occlusione: Nell’immagine compaiono solo gli oggetti che intercettano per primi le linee di visioni che partono dal centro focale C, ovviamente.
Modello CAHV
: Centro focale; : Versore Z; : Versore X; : Versore Y
Permette una visualizzazione più comoda del sistema di riferimento della videocamera se questa è in movimento, e inoltre, può descrivere un piano dell’immagine non allineato al sistema di riferimento della videocamera (distorsione del sistema ottico).
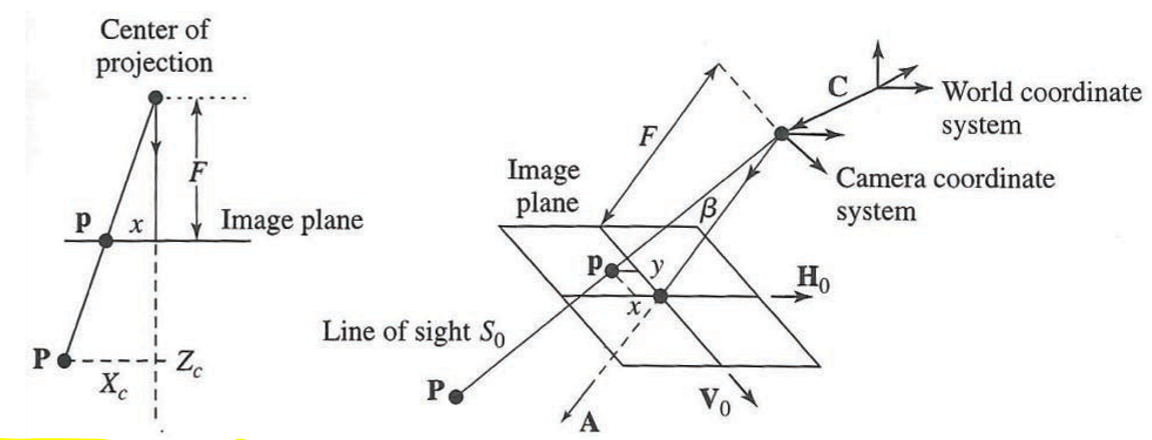
Dalle formule sulle proiezioni prospettiche, ricaviamo:
Dove:
è la traslazione dall’origine; - I versori A,H,V sono trasposti perché normalmente troviamo i vettori in colonna, qui li rappresentiamo in riga.
Essenzialmente questo modello applica un cambio di sistema di riferimento, dato che si ha una traslazione dell’origine.
Movimenti
Spostamenti in 3D e 2D
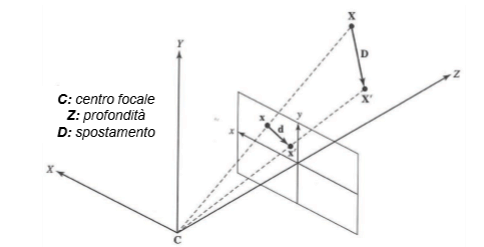
Siano:
-
Posizione iniziale a
-
-
Posizione finale a
-
-
Spostamento 3D:
-
Spostamento 2D:
-
D è il vettore di spostamento, il displacement.
Modelli di movimento in 2D
Quando abbiamo degli istanti
Un altro nome per
Un’insieme di motion vector per ogni

Esempio di Motion Field.
Funzione di mapping
Ci interessa sapere il movimento di tutti gli elementi della immagine (a seconda della separazione che utilizziamo, pixel, blocchi, etc…).
Ogni pixel contiene un valore diverso da quello iniziale. All’inizio,
Se ci sono molti elementi
Movimenti della Telecamera
| Traslazione | Asse Perno | Rotazione |
|---|---|---|
| Tracking | Tilting | |
| Booming | Panning | |
| Dollying | Rolling |
- Con Z: asse perpendicolare all’immagine (di profondità), e Y: asse altezza.
- Potrebbe non essere immediatamente chiaro nel contesto delle rotazioni: immagina di utilizzare l’asse di rotazione appunto come ‘perno’ su cui la telecamera ruota.
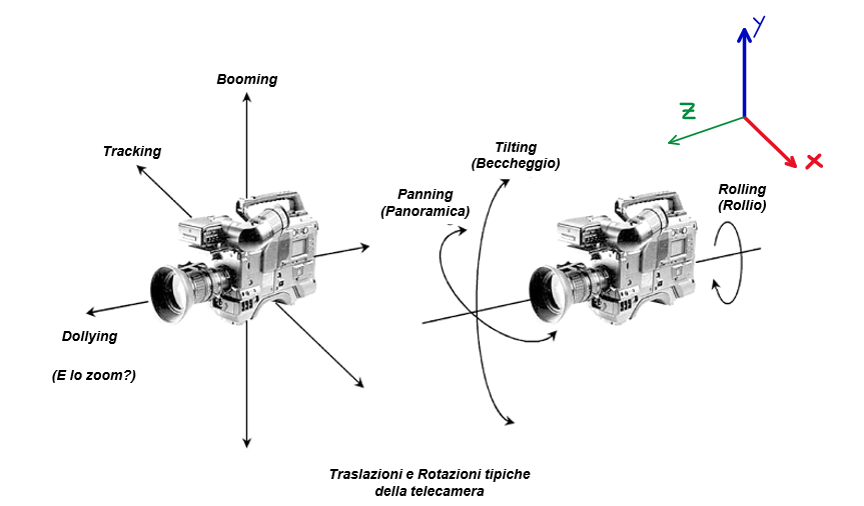
Dollying != Zooming
Tracking, Booming
Si aggiungono due costanti,
I cambiamenti di coordinate nel sistema 3D sono:
Nel sistema 2D invece:
Di fatto, è una traslazione. Andiamo a sommare alla posizione originale il valore di cui ci siamo spostati.
L’approssimazione (ortografica) del motion field è:
Zooming
Zoom(
Nello Zooming si conservano le relazioni spaziali.
I cambiamenti in 2d:
E l’approssimazione del motion field:
Differenze Dolly e Zoom
Lo Zoom è una variazione della focale. Difatti
Questo comportamento è facilmente intuibile anche usando la formula:
Inoltre, anche dalla formula, notiamo che lo zoom non dipende dalla
Tilt, Pan approssimato (fatta molto velocemente)
Fondamentalmente, tutte le rotazioni derivano da matrici di rotazioni vere e proprie, come è facile immaginare. L’approssimazione funziona se assumiamo che:
In altre parole, le operazioni non dipendono dalla posizione nel frame, ma solo dai
Se non valgono le condizioni specificate pocanzi, non vale più la matrice di rotazione
Roll
Roll dipende dalle coordinate, infatti la posizione centrale resta invariata.
Modello a 4 parametri
- Consideriamo il caso in cui una telecamera effettua in sequenza: boom, tracking, pan, tilt, zoom e rolling;
- Usando le approssimazioni viste in precedenza è possibile mappare una funzione a 4-parametri che riassume tutte le trasformazioni;
- Se l’ordine dovesse cambiare, la formula rimarrebbe valida, ma cambierebbero le relazioni fra i 4-parametri e i parametri delle singole trasformazioni.
Tutta la matrice di trasformazione non viene chiesta all'esame (di solito)
Gioitene tutti 😇
Il modello a 4-parametri è un caso particolare di trasformazione affine (affine mapping) normalmente a 6 parametri, prende il nome di trasformazione geometrica (geometric mapping), e caratterizza qualsiasi combinazione di scaling, rotazione e traslazione in 2D.
Modello a 6 parametri
- La rotazione di un oggetto attorno all’origine dello spazio 3D è data dalla matrice di rotazione:
che non ricopio completa qui perché dovrebbero pagarmi.
Cose importanti da ricordare:
- Sebbene la matrice ha 9 elementi, essa è determinata solo da 3 angoli di rotazione.
- Le relazioni che otteniamo sono note come il caso generale del mapping di traslazioni e rotazioni arbitrarie da spazio 3D a spazio 2D
- Rispetto al modello a 4-parametri, con questo modello a 6-parametri è possibile considerare anche traslazioni lungo l’asse Z (dollying) e rotazioni attorno ad assi arbitrari.
Rappresentazione del Movimento
Come rappresentare però i motion field?
Evitiamo una rappresentazione globale, dato che non funziona bene se nella scene sono presenti più oggetti che si muovono in maniera differente.
Evitiamo però anche una rappresentazione basata sui singoli pixel che compongono l’immagine, dato che richiede la stima di troppi vettori di movimento.
I criteri che funzionano sono:
- Rappresentazione basata su regione: segmentiamo l’immagine in regioni con algoritmi di edge detection.
- Computazionalmente oneroso, potrebbe risultare difficile da generalizzare;
- Rappresentazione basata su blocchi:
- Buon compromesso fra accuracy e complexity;
- Problemi di discontinuità solo sul bordo dei blocchi (risolvibile)
Nella rappresentazione basata su blocchi ricordo come si sono spostati i blocchi e la differenza tra la stima effettuata e il movimento reale.
Criteri di Stima del Movimento
Displaced Frame Difference (DFD)
Siano:
- Anchor frame
a il frame iniziale; - Target Frame
a il frame su cui stimare il relativo movimento: backward motion estimation; forward motion estimation Il nostro obiettivo sarà minimizzare la differenza.
Definiamo inoltre una funzione di mapping:
Dove sono i parametri di movimento (da stimare!).
Stiamo essenzialmente tentando di capire che tipo di spostamento è avvenuto.
Errore DFD
Dove:
insieme dei pixel nell’anchor frame ; intero positivo; casi particolari: è detto mean absolute difference (MAD) è detto mean squared error (MSE) L’errore è calcolato nel frame trasformato e il frame immediatamente prima.
Ragionamento
Sappiamo che la derivata di una funzione si azzera nei punti di minimo e massimo. Dato che vogliamo minimizzare l’errore, prendiamo la derivata.
Affinchè la stima dei parametri
- Essendo
un vettore, dovremo in generale imporre che il gradiente di . - Ad esempio, per
(MSE) il gradiente sarà:
Dove
Block Matching Algorithm (BMA)
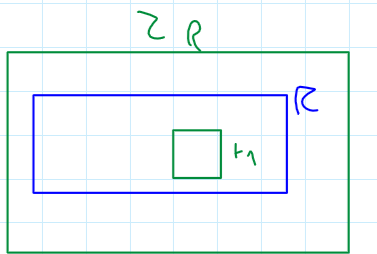
Consideriamo la rappresentazione di movimento basata su blocchi.
- I blocchi possono avere qualsiasi forma geometrica, ma per semplicità assumiamo che siano quadrati.
- Devono rispettare le seguenti leggi:
- Cioè l’unione di tutti i blocchi restituisce l’intero frame (
), e l’intersezione di tutti i blocchi restituisce un insieme vuoto (non vi è sovrapposizione tra frame). - Assumiamo inoltre che tutti i pixel di un blocco
si muovano nella stessa direzione, con un MV per blocco (modello traslazionale blockwise). - Dato l’anchor frame(?)
vogliamo trovare il target frame che minimizza l’errore DFD.
BMA Esaustivo (EBMA)
Cioè vogliamo minimizzare:
Per trovare il migliore
Tutto questo processo è molto oneroso computazionalmente. Per ridurre il carico si può usare la Mean Absolute Difference (MAD Error).
Solitamente si una un passi di ricerca pari a 1 pixel (integer-per-pixel accuracy search.).
Sia
- Dovendo fare una sottrazione, un valore assoluto e un’addizione, per ogni blocco ci sono
operazioni. - Numero di operazioni per stimare un MV per blocco:
- La formula rappresenta tutti i possibili spostamenti di un blocco nella regione di ricerca. Il +1 c’è per gestire il caso in cui rimango fermo.
Siano ora
Avremo quindi
Il numero totale di operazioni sarà quindi
Questo risultato è interessante perché il carico computazionale è indipendente dalla dimensione dei blocchi.
Difatti, dipende solo dalla dimensione del frame (dell’immagine), e dalla dimensione della regione di ricerca.
Resta comunque molto pesante, computazionalmente parlando, quindi serve un metodo più veloce.
Three-Step Search
Modifichiamo l’EBMA:
- Per trovare il migliore
confrontiamo i fra l’anchor frame e un sottoinsieme dei possibili target frame all’interno di una regione di ricerca. - Si inizia con un passo di ricerca
uguale (o leggermente maggiore) alla metà del raggio di ricerca R; - Ad ogni passo dell’algoritmo ri riduce il passo di ricerca della metà, finché non sarà pari a 1
- Effettuiamo infine EBMA solo su una ragione molto più piccola (quella probabile).
- In un intorno di 8 punti, +1 quello in cui mi trovo già.
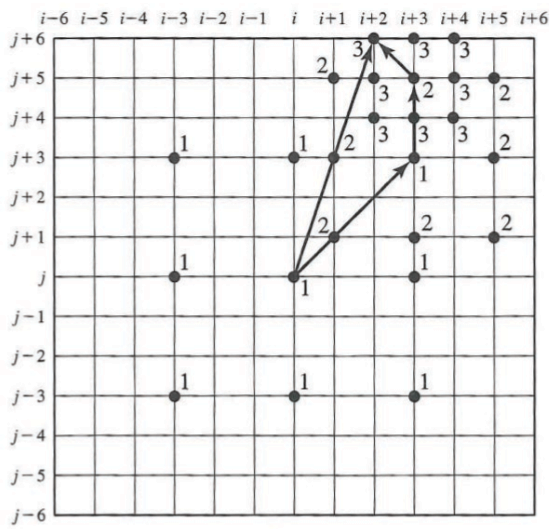
- Al primo passo:
- Si calcola il miglior MV su 9 punti di ricerca entro un raggio di ricerca
- Si calcola il miglior MV su 9 punti di ricerca entro un raggio di ricerca
- Dal secondo passo in poi:
- Si pone
- Si calcola il miglior MV su 8 punti di ricerca entro un raggio di ricerca
- Se reitera finché
- Si pone
Nota bene: a dispetto del nome, potrebbero esserci più di tre passi di ricerca. In casi particolari potremmo anche non trovare effettivamente il minimo ottimo, ma quanto meno siamo vicini.
RISPOSTA DOMANDA ESAME❗ :
formula fondamentale da ricordare. Quesito: Alla fine dell’esecuzione di un’istanza dell’algoritmo di block matching Three-Step-Search si osserva che per un singolo blocco sono stati visitati 73 punti di ricerca. Qual è il passo di ricerca iniziale R0?
Procedimento:
; Sappiamo che sono stati visitati 73 punti. In ogni passo di ricerca io visito 8 punti+1, quindi, con
punti di ricerca:
;
Sostituendo nella formula precedente:
Elevando entrambi i membri, ottengo:
Che mi restituisce il passo di ricerca iniziale
, quello che stavo cercando.
Features from Accelerated Segment Test (FAST)
Algoritmo per estrarre punti chiave “Features from Accelerated Segment Test”.
Individua dei punti salienti (corner) nel frame, da usare come features per tracciare il movimento.
- Si analizza ad ogni passo un insieme di 16 punti con configurazione a cerchio di raggio 3 per classificare se un punto
sia di corner o meno. - Data l’intensità
del punto , se per almeno 12 punti contigui con l’intensità si ottiene che , con soglia, allora sarà un punto di corner. - Quindi, non andiamo a prendere tutti i blocchi, ma individuiamo dei keypoints.
In altre parole, stiamo confrontando la luminanza del centro con la luminaza dei possibili punti corner.
Si fanno le differenze in valore assoluto, se almeno 12 punti consecutivi superano la soglia, allora il punto analizzato ci interessa.
La soglia
Dato un Cerchio di Bresenham di raggio 3:
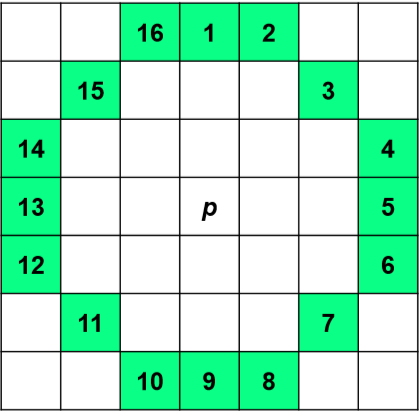
Ci devono essere almeno
RISPOSTA DOMANDA ESAME❗ :
Questo punto P è di corner?
Sì, se ci sono 12 punti consecutivi la cui differenza supera la soglia, altrimenti no!
Formula da utilizzare (come sopra):
Se un qualsiasi passaggio è falso, allora possiamo già escludere il punto.
Inoltre, possiamo semplificare il calcolo: invece di prendere i punti sequenzialmente, eseguiamo il calcolo nei punti che potrebbero interrompere la sequenza consecutiva:
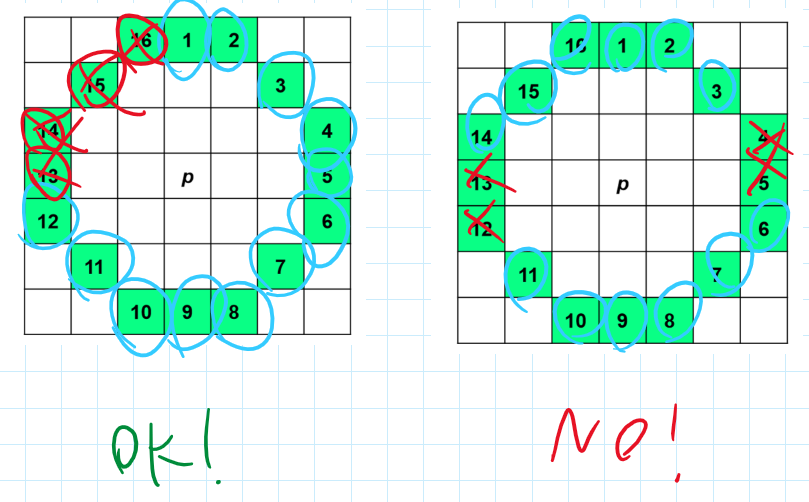
Un’altra possibile semplificazione è quella di calcolare i punti nell’intorno del primo punto preso in considerazione:
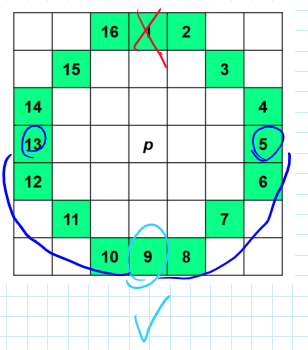
High-Speed Test
Questo procedimento di semplificazione si chiama infatti ”High Speed Test”. Formalmente:
- Verificare
per i punti del cerchio in posizioni che potrebbero interrompere la sequenza, ad esempio nei punti 1 e 9, e poi 5 e 13. - Se per almeno 2 di questi 4 punti il test risulta
il punto non può essere di corner.
FAST + High Speed Test è più veloce di altri metodi, sebbe meno preciso. Questo le rende adatto per applicazioni real time.
Perché Stimare il movimento?
L’informazione sul movimento della scena torna utile in vari modi:
- Stabilizzazione Video;
- Compressione Video;
- Ricostruzione della scena 3D a partire dalla proiezione 2D;
- etc…